OK. Last one for today. I’m not going to go into too much detail except to say that the offending piece of code loads all items in a ‘matrix’ database table and builds a business object collection hierarchy. This table has 4 fields, one or more of which may be NULL – for different meanings. I really don’t particularly like this type of approach but changing it right now would involve quite a bit of work.
The table looks something like
Level1ID
Level2aID
Level2bID
Level2cID
This ultimately translates to a business object hierarchy of:
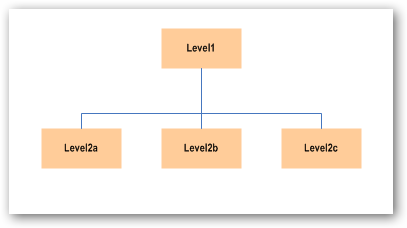
- Rows with Level1ID (only) – all other fields null – are Level1 objects
- Rows with Level1ID and Level2a ID (only) are Level2a objects
etc…
The matrix table just contains the primary keys for each object so the code loads each one in the style below…
Load matrix
for each row in matrix
{
if row type == Level1
Add to Level1Collection
else if row type == Level2a
{
Load Level2a object
Add Level2a object to Level1[Level1ID].Level2aCollection
}
else if row type == Level2b
{
Load Level2b object
Add Level2b object to Level1[Level1ID].Level2bCollection
}
else if row type == Level2c
{
Load Level2c object
Add Level2c object to Level1[Level1ID].Level2cCollection
}
}
This seems reasonable enough (logical anyway) given the way the data’s being retrieved.
This does however load another several hundred rows from more stored proc calls that load each new object into the child collections. This whole thing consistently takes around 8 seconds.
The Refactoring
A wise man once told me that if you can be sure the bulk of your operation is data access then lump it all together if you can, and do the loop or other grunt processing on the client.
- I created a new Stored Procedure to return 4 result sets. These come back as 4 tables in the target DataSet. Each resultset is qualified by the same master criteria, and just uses joins to get a set of data that can be loaded directly into the collections. The original stored proc is no longer required and this is now the only data access call.
- I changed my collection classes slightly to allow a LoadData method which takes in a dataset, a tablename and a parent key. This means I can add Level2a objects to the appropriate Level1 collection. The pseudo code now looks like…
Load multiple results
for each row in matrix
{
if Level1 Results present
LoadData on Level1Collection
if Level2a Results present
for each Level1 row
LoadData on Level1[Level1ID].Level2aCollection
if Level2b Results present
for each Level1 row
LoadData on Level1[Level1ID].Level2bCollection
if Level2c Results present
for each Level1 row
LoadData on Level1[Level1ID].LevelcbCollection
}
As I said at the beginning, there are some definite improvements to be made from changing the data structure, and a lot of this code could look a lot nicer by using Typed Datasets with relationships defined.
The new approach actually completes in less than 100ms. I couldn’t actually believe it myself, and made sure I killed connections, cache etc to make sure the database was coming in cold. Still the same.
This basically proves that for data-heavy operations, things really start to hurt when you’re making repeated client round-trips, however small the call. This is basically a 99% saving in load time for this business object.
The resulting page is also really snappy now and I’m sure the customer won’t even notice 🙂