As it’s Friday I thought – let’s do some cleaning up. The following exercise is refactoring a class from an app I’m maintaining at the moment. The app’s fine (functional etc), and was originally a .NET 1.1 build. A combination of this, a previous, straight conversion to .NET 2.0 (with the minimum of mods) and a variety of historical developers (mostly junior) means that the code has a certain amount of ‘odour’ in numerous places.
Lack of consistency isn’t the main problem, it’s more about doing things smartly rather than taking the path of least resistance with your current knowledge. The latter generally means you don’t learn much, get much satisfaction or pride in your work, and you may end up a tad confused as to why you always end up with the ‘less glamourous’ projects.
Here’s the original code. A simple collection class containing custom MenuItem objects.
/// <summary>
/// Represents a collection of MenuItems.
/// </summary>
public class MenuItems
{
private readonly ArrayList palMenuItems = new ArrayList();
// Add a MenuItem to the Collection
public void Add(MenuItem objMenuItem)
{
palMenuItems.Add(objMenuItem);
}
// Retrieve a MenuItem from the Collection
public MenuItem Item(string strTitle)
{
if (palMenuItems.Count > 0)
{
foreach (MenuItem objMenuItem in palMenuItems)
{
if (objMenuItem.Title.ToLower() == strTitle.ToLower())
{
return objMenuItem;
}
}
}
return new MenuItem();
}
// Returns True if the specified Key exists in the collection
public bool Exists(string strTitle)
{
if (palMenuItems.Count > 0)
{
foreach (MenuItem objMenuItem in palMenuItems)
{
if (objMenuItem.Title.ToLower() == strTitle.ToLower())
{
return true;
}
}
}
return false;
}
// Remove a MenuItem from the Collection
public void Remove(string strTitle)
{
if (palMenuItems.Count > 0)
{
foreach (MenuItem objMenuItem in palMenuItems)
{
if (objMenuItem.Title.ToLower() == strTitle.ToLower())
{
palMenuItems.Remove(objMenuItem);
break;
}
}
}
}
// Clear the collections contents
public void Clear()
{
palMenuItems.Clear();
}
// Return the Number of MenuItems in the Collection
public int Count()
{
return palMenuItems.Count;
}
// Access to the enumerator
public MenuItemEnumerator GetEnumerator()
{
return new MenuItemEnumerator(this);
}
#region MenuItem Enumaration Class
//=================================================================================================
// Inner Enumeration Class:
//=================================================================================================
public class MenuItemEnumerator
{
private readonly MenuItems pMenuItems;
private int position = –1;
public MenuItemEnumerator(MenuItems objMenuItems)
{
pMenuItems = objMenuItems;
}
public MenuItem Current
{
get { return (MenuItem) pMenuItems.palMenuItems[position]; }
}
// Declare the MoveNext method required by IEnumerator:
public bool MoveNext()
{
if (position < pMenuItems.palMenuItems.Count – 1)
{
position++;
return true;
}
else
{
return false;
}
}
// Declare the Reset method required by IEnumerator:
public void Reset()
{
position = –1;
}
// Declare the Current property required by IEnumerator:
}
#endregion
}
Colorized by: CarlosAg.CodeColorizer
OK – Here’s the issues I see with the code.
- You can spot some room for improvement immediately with variable naming (a weird variation of hungarian notation) – palMenuItems, objMenuItems etc.
- This is a simple wrapper implementation. In conjunction with the naming you may conclude this is an ex-VB programmer who hasn’t quite grasped object-oriented concepts yet (an observation – not a criticism). If the developer knew about inheritance then they would have hopefully just inherited from one of the many applicable classes in System.Collections. This would have also removed the need for implementing a custom Enumerator class. Note that neither class actually inherits from any useful base class. This is copy/paste pseudo-inheritance, and is rarely a wise idea.
- The Exists and Item methods use a simple loop mechanism to find the item they’re looking for. This is potentially wasteful with many items, and goes back to the ‘path of least resistance’ thought. It’s also using the inefficient ‘ToLower’ implementation to do comparison of what should be a key. In practice the match doesn’t need to be case-insensitive, and if it did then a String.Compare should be used with the appropriate ‘ignorecase’ argument). The developer clearly isn’t familiar (or maybe just not comfortable) with dictionaries or hashtables where access to items via a key is supported and far more efficient.
- The Count implementation is a method rather than a property (aargh!)
- It could be argued that the menuitem class itself (not shown here) is redundant as the ASP.NET framework does define a similar MenuItem class. In reality the whole implementation could be replaced with a sitemap, a menu control, and some custom code, but I’ll leave that out of scope for now.
That gives some pointers as to what ‘could’ have been done in .NET 1.1. .NET 2.0 of course introduced generics and so let’s follow that path.
The MenuItems class is used in a few places:
- A menu control (that renders menu items)
- Many pages that load items into the control (I already refactored some of this into inherited menu controls, where all pages shared the same ‘dynamic’ menu), but there’s plenty more improvements to be made.
The first thing is to say…
I don’t need a collections class…
The following is now in the Menu Control:
//private MenuItems menuItems = new MenuItems(); – Out with the Old
private Dictionary<string, MenuItem> menuItems = new Dictionary<string, MenuItem>(); //In with the new
public Dictionary<string, MenuItem> MenuItems
{
get { return menuItems; }
set { menuItems = value; }
}
Colorized by: CarlosAg.CodeColorizer This simply uses a generic Dictionary object with a string key (as we find items by title). Anywhere that references this dictionary will now need to add a ‘key’ in certain places (e.g. Add method), and the Item method will no longer work as that’s gone. That needs to change to a class indexer.
Fortunately Visual Studio’s find and replace can cope with all of this as the code is largely consistent…
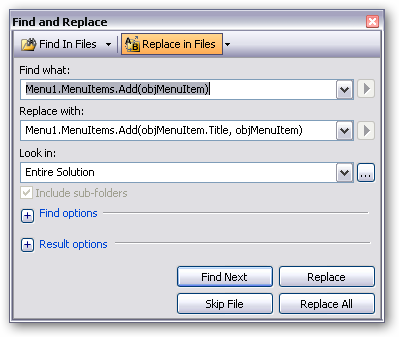
A quick compile should show all the patterns (from the errors) if there’s any inconsistencies. There were probably about 200 references to patch here with about 4 different variations of naming and scope – but it took about 5 minutes to patch (including writing this text :-))
We then have to patch all the ‘Item’ references. These are almost always setting a ‘selected’ property (Stopwatch on…)
As there’s only a few references here (about 20), I could patch them manually, but this could be done entirely by using regular expressions to do the find and replace. http://msdn.microsoft.com/en-us/library/2k3te2cs.aspx shows all the options available. I tend to only use regexp for large volume stuff where I get a return on my time investment to work out the expression!
I’m just doing it in two steps without regexp as follows:
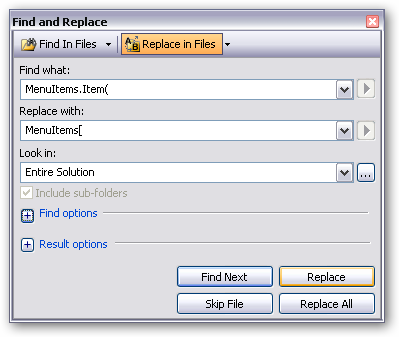
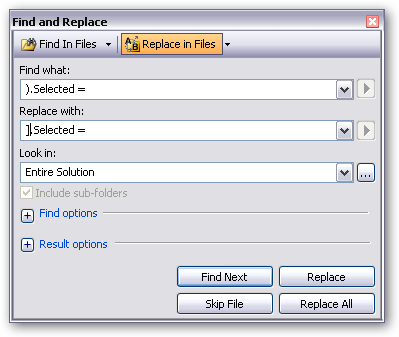
The code
Menu1.MenuItems.Item(UserMenu.MyCommunicationItems).Selected = true;
becomes
Menu1.MenuItems[UserMenu.MyCommunicationItems].Selected = true;
For extra points you then use Resharper to rename all of the obj and pal references to something reasonable, e,g, objMenuItem becomes menuItem.
Oh – and use Resharper’s ‘Find Usages’ on the MenuItems class to confirm it can be deleted.
And relax…..
In hindsight I would have used Resharper to ‘change signature’ on the methods in MenuItems (to patch all the references first), then converted to the generic Dictionary. Could have been a bit quicker.
Hope this gives someone some courage to get in there and improve their code. I firmly believe you’ve just got to ‘want’ to do it and then you’re biggest problem will be stopping yourself!
{kind=link}